

Bag of Words(BOW)
문서가 가지는 모든 단어를 문맥이나 순서를 무시하고 일괄적으로 단어에 대해 빈도 값을 부여해 피처 값을 추출하는 모델
- 문장에 있는 모든 단어에서 중복을 제거하고(여기 인덱스 부여할때만!) 각 단어를 칼럼 형태로 나열함. 그리고 각 단어에 고유의 인덱스를 부여. ex) ‘and’:0, ‘baseball’;1 …
- 개별 문장에서 해당 단어가 나타나는 횟수를 각 단어(단어 인덱스)에 기재함.

단점 1.
문맥 의미 반영 부족
: 단어의 순서를 고려하지 않기 때문에 문장 내 문맥적 의미가 무시됨.
단점 2.
희소 행렬 문제
: 많은 문서에서 단어를 추출하면 매우 많은 단어가 칼럼으로 만들어지고, 문서마다 서로 다른 단어로 구성되기에 단어가 문서마다 나타나지 않는 경우가 훨씬 많음.
⇒ 매우 많은 문서에서 단어의 총 개수는 수만~수십만개가 될 수 있는데, 하나의 문서에 있는 단어는 극히 일부분이므로 대부분 데이터는 0값으로 채워짐. → 희소행렬
↔ 밀집 행렬 : 대부분의 값이 0이 아닌 의미 있는 값으로 채워져 있는 행렬
- BOW 피처 벡터화
텍스트를 특정 의미를 가지는 숫자형 값인 벡터 값으로 변환하는 것.
: 각 문서의 텍스트를 단어로 추출해 피처로 할당하고, 각 단어의 발생 빈도와 같은 값을 이 피터에 값으로 부여해 각 문서를 이 단어 피처의 발생 빈도 값으로 구성된 벡터로 만드는 기법
ex) M개의 텍스트 문서가 있고, 이 문서에서 모든 단어를 추출해 나열했을 때 N개의 단어가 있다고 가정하면 문서의 피처 벡터화를 수행하면 M개의 문서는 각각 N개의 값이 할당된 피처의 벡터 세트가 됨. 결국, M X N개의 단어 피처로 이뤄진 행렬 구성.
1. 카운트 기반의 벡터화 (CountVectorizer)
단어 피처에 값을 부여할 때 각 문서에서 해당 단어가 나타나는 횟수, 즉 Count를 부여하는 경우.
카운트 값이 높을 수록 중요한 단어로 인식됨.
→ 문장에서 자주 사용될 수 밖에 없는 단어까지 높은 값을 부여하게 됨.
2. TF-IDF 벡터화
: 개별 문서에서 자주 나타나는 단어에 높은 가중치를 주되, 모든 문서에서 전반적으로 자주 나타나는 단어에 대해서는 페널티를 주는 방식으로 값을 부여함.
TFIDFi = TFi*log(N/DFi)
(TFi = 개별 문서에서 단어 i 빈도 / DFi = 단어 i를 가지고 있는 문서 개수 / N = 전체 문서 개수)
단어 i를 가지고 있는 개수가 많으면(전반적으로 자주 나타나면) DFi값은 커지고, N/DFi 값이 작아질 거니까.
- 사이킷런의 Count 및 TF-IDF 벡터화 구현 : CountVectorizer, TfidfVectorizer
- CountVectorizer
: 소문자 일괄 변환, 토큰화, 스톱워드 필터링, 피처 벡터화 등 다 함께 수행.
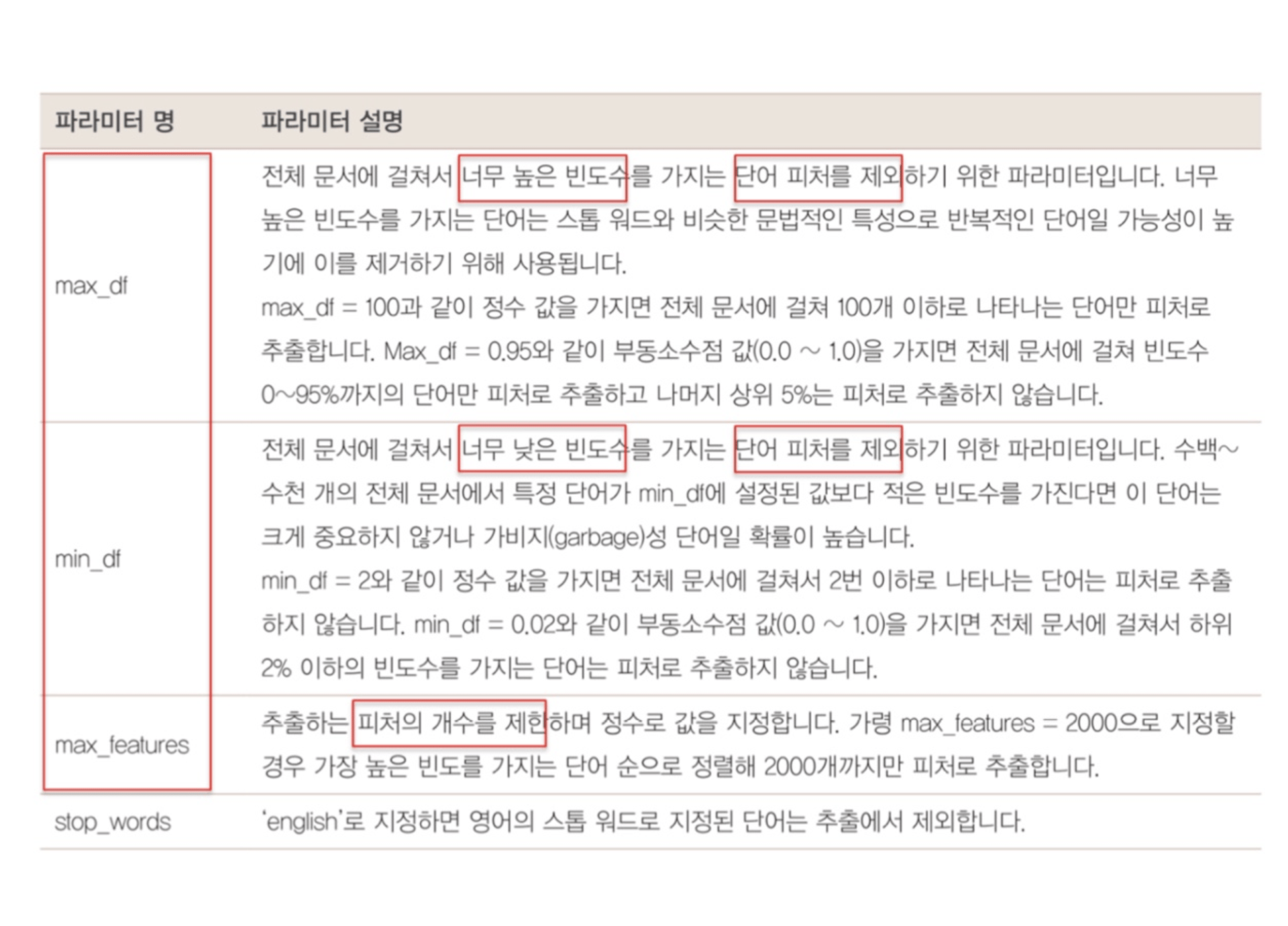
+n_gram_range, analyzer, token_pattern, tokenizer 파라미터도 있음.
-stop_words는 파라미터가 주어진 경우 스톱 워드 필터링만 가능.
-stemming과 lemmatization 같은 어근 변환은 CountVectorizer에서 직접 지원하진 않으나 tokenizer 파라미터에 커스텀 어근 변환 함수를 적용하여 어근 변환 수행.

- BOW 벡터화를 위한 희소 행렬
텍스트를 피처 단위로 벡터화해 변환하고 CSR 형태의 희소행렬 반환.
대규모 행렬의 대부분의 값을 0이 차지하는 행렬을 희소 행렬이라함. BOW 형태를 가진 언어 모델의 피처 벡터화는 대부분 희소행렬임.
→ 물리적으로 적은 메모리 공간을 차지할 수 있도록 변환해야하는데 COO 형식과 CSR 형식이 있음.
- 희소행렬 저장 방식 : COO 방식
COO 형식은 0이 아닌 데이터만 별도의 데이터 배열에 저장하고, 그 데이터가 가리키는 행과 열의 위치를 별도의 배열로 저장하는 방식.

import numpy as np
dense = np.array([[3,0,1],[0,2,0]])
from scipy import sparse
# 0이 아닌 데이터 추출
data = np.array([3,1,2])
# 행 위치와 열 위치를 각각 배열로 생성
rows_pos = np.array([0,0,1])
col_pos = np.array([0,2,1])
sparse_coo = sparse.coo_matrix((data, (rows_pos, col_pos)))
sparse_coo.toarray()
#하면 다시 원래 밀집형태의 행렬로 출력됨.
- 희소행렬 저장 방식 : CSR 방식
CSR 형식은 COO 형식이 행과 열의 위치를 나타내기 위해 반복적인 위치 데이터를 사용해야하는 문제점을 해결한 방식.

-여기서 행 위치 배열 보면 0이 2번, 1이 5번 반복되고 있음.
→ 행 위치 배열이 0부터 순차적으로 증가하는 값으로 이뤄졌다는 특성을 고려하면 행 위치 배열의 고유한 값의 시작 위치만 표기하는 방법으로 이러한 반복 제거 가능(어차피 숫자는 순차적으로 커지니 0다음엔 1나오고 2나올게 뻔하니까)
⇒ CSR은 행 위치 배열 내에 있는 고유한 값의 시작 위치만 다시 별도의 위치 배열로 가지는 변환 방식

from scipy import sparse
dense2 = np.array([[0,0,1,0,0,5],
[1,4,0,3,2,5],
[0,6,0,3,0,0],
[2,0,0,0,0,0],
[0,0,0,7,0,8],
[1,0,0,0,0,0]])
# 0이 아닌 데이터 추출
data2 = np.array([1,5,1,4,3,2,5,6,3,2,7,8,1])
# 행 위치와 열 위치를 각각 배열로 생성
rows_pos = np.array([0,0,1,1,1,1,1,2,2,3,4,4,5])
col_pos = np.array([2,5,0,1,3,4,5,1,3,0,3,5,0])
#COO형식으로 변환
sparse_coo = sparse.coo_matrix((data2, (rows_pos, col_pos)))
# 행 위치 배열의 고유한 값의 시작 위치 인덱스를 배열로 생성
row_pos_ind = np.array([0,2,7,9,10,12,13])
#CSR 형식으로 변환
sparse_csr = sparse.coo_matrix((data2, (col_pos, row_pos_ind)))
실제 사용시,,,
coo = sparse.coo_matrix(dense3)
csr = sparse.csr_matrix(dense3)
#희소행렬의 메모릴 줄이는 법!사이킷런의 Vectorizer 클래스로 변환된 피처 백터화 행렬은 모두 사이파이 CSR 형태의 희소 행렬임.
'Machine Learning > 텍스트 분석' 카테고리의 다른 글
| [파이썬 머신러닝 가이드] 텍스트 분석 - 문서 군집화 (2) | 2023.12.26 |
|---|---|
| [파이썬 머신러닝 가이드] 텍스트 분석 - 토픽 모델링 (1) | 2023.12.26 |
| [파이썬 머신러닝 가이드] 텍스트 분석 - 감성 분석 (2) | 2023.12.26 |
| [파이썬 머신러닝 가이드] 텍스트 분석 - 텍스트 분류 실습(20 뉴스그룹 분류) (2) | 2023.12.26 |
| [파이썬 머신러닝 가이드] 텍스트 분석 - 텍스트 전처리(정규화) (2) | 2023.12.26 |