

문서 유사도
문서와 문서 간의 유사도 비교는 일반적으로 코사인 유사도(Cosine Similarity)를 사용함.
** 코사인 유사도 : 벡터와 벡터 간의 유사도를 비교할 때 벡터의 크기보다는 벡터의 상호 방향성이 얼마나 유사한지에 기반함. → 두 벡터의 사잇각을 구해서 얼마나 유사한지 수치로 적용
- 두 벡터 사잇각
A * B = ||A||||B||cosθ
따라서, 유사도 cosθ는 두 벡터의 내적을 총 벡터 크기의 합으로 나눈 것 (내적 결과를 총 벡터 크기로 정규화한 것)
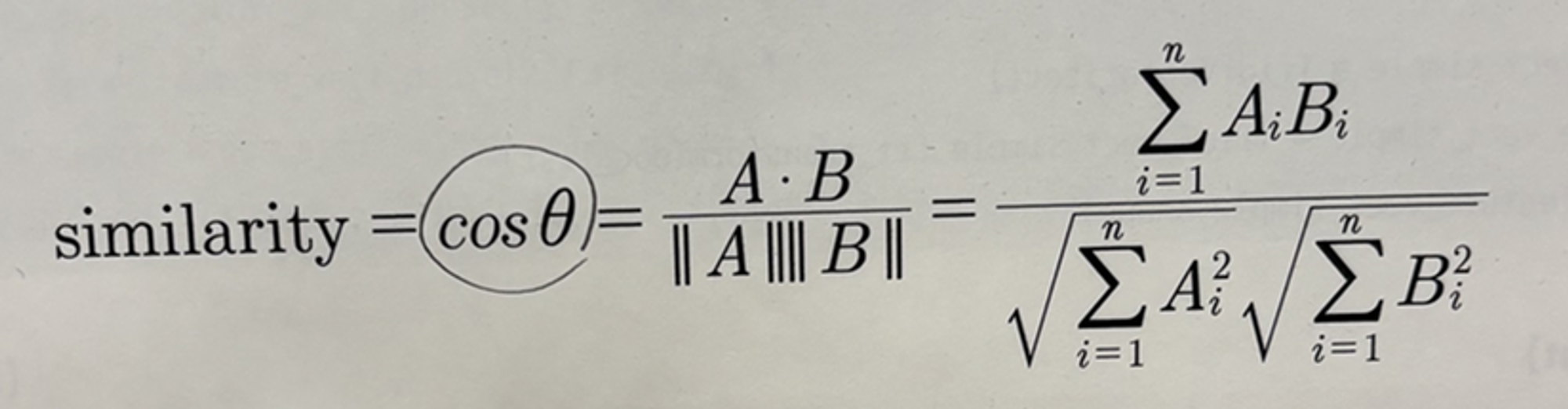
**코사인 유사도가 문서의 유사도 비교에 가장 많이 사용되는 이유
: 문서를 피처 벡터화 변환하면 차원이 매우 많은 희소 행렬이 되기 쉬움. 희소 행렬 기반에서 문서와 문서 벡터 간의 크기에 기반한 유사도 지표(ex.유클리드)는 정확도가 떨어지기 쉬움.
: 문서가 매우 긴 경우 빈도수도 더 많을 것이기 때문에 빈도수에만 기반해서는 공정한 비교 불가.
ex) A 문서에서 머신러닝 5번 언급, B 문서에서 3번 언급 + A 문서가 B 문서보다 10배 이상 크다면 오히려 B 문서가 머신러닝과 더 밀접한 관련. (크기에 비해 언급이 많이 된거니까)
cos_similarity() 함수 사용
import numpy as np
def cos_similarity(v1, v2):
dot_product = np.dot(v1, v2)
l2_norm = (np.sqrt(sum(np.square(v1))) * np.sqrt(sum(np.square(v2))))
similarity = dot_product / l2_norm
return similarityfrom sklearn.feature_extraction.text import TfidfVectorizer
doc_list = ['if you take the blue pill, the story ends' ,
'if you take the red pill, you stay in Wonderland',
'if you take the red pill, I show you how deep the rabbit hole goes']
tfidf_vect_simple = TfidfVectorizer()
feature_vect_simple = tfidf_vect_simple.fit_transform(doc_list) # 이 행렬은 희소행렬임.
print(feature_vect_simple.shape)
#(3,18) -> 3개의 문서(문장), 18개의 피처
cos_similarity() 함수의 인자인 array로 만들기 위해 밀집 행렬로 변환한 뒤 다시 각각의 배열로 변환함.
# TFidfVectorizer로 transform()한 결과는 Sparse Matrix이므로 Dense Matrix로 변환.
feature_vect_dense = feature_vect_simple.todense()
#첫번째 문장과 두번째 문장의 feature vector 추출
vect1 = np.array(feature_vect_dense[0]).reshape(-1,)
vect2 = np.array(feature_vect_dense[1]).reshape(-1,)
#첫번째 문장과 두번째 문장의 feature vector로 두개 문장의 Cosine 유사도 추출
similarity_simple = cos_similarity(vect1, vect2 )
print('문장 1, 문장 2 Cosine 유사도: {0:.3f}'.format(similarity_simple))
+사이킷런의 코사인 유사도 측정 API : cosine_similarity(비교 기준이 되는 문서의 피처행렬, 비교되는 문서의 피처행렬) → 희소행렬, 밀집행렬, 배열 모두 가능
from sklearn.metrics.pairwise import cosine_similarity
similarity_simple_pair = cosine_similarity(feature_vect_simple[0] , feature_vect_simple) #비교 기준이 되는 문서가 [0]인건 첫번째 문서와 비교하고 있는 것임.
print(similarity_simple_pair)
#[[1. 0.40207758 0.40425045]] -> 바로 자신 문서인 첫번째 문서, 두번째, 세번째 문서의 유사도를 측정하고 있는 것임.
+쌍으로 코사인 유사도 값을 알 수도 있음.(ndarray 형태로)
similarity_simple_pair = cosine_similarity(feature_vect_simple , feature_vect_simple)
print(similarity_simple_pair)
print('shape:',similarity_simple_pair.shape)[[1. 0.40207758 0.40425045]
[0.40207758 1. 0.45647296]
[0.40425045 0.45647296 1. ]]
shape: (3, 3)'Machine Learning > 텍스트 분석' 카테고리의 다른 글
| [파이썬 머신러닝 가이드] 텍스트 분석 - 한글 텍스트 처리, 텍스트 분석 실습 (2) | 2023.12.26 |
|---|---|
| [파이썬 머신러닝 가이드] 텍스트 분석 - 문서 군집화 (2) | 2023.12.26 |
| [파이썬 머신러닝 가이드] 텍스트 분석 - 토픽 모델링 (1) | 2023.12.26 |
| [파이썬 머신러닝 가이드] 텍스트 분석 - 감성 분석 (2) | 2023.12.26 |
| [파이썬 머신러닝 가이드] 텍스트 분석 - 텍스트 분류 실습(20 뉴스그룹 분류) (2) | 2023.12.26 |