

스태킹 앙상블
스태킹, 배깅(각각의 분류기가 모두 같은 유형, vs. 보팅), 부스팅 모두 개별적인 여러 알고리즘을 서로 결합해 예측 결과 도출
**가장 큰 차이점 = 스태킹은 개별 알고리즘으로 예측한 데이터를 기반으로 다시 예측을 수행한다는 것.
= > 개별 알고리즘의 예측 결과 데이터 세트를 최종적인 메타 데이터 세트로 만들어 별도의 ML 알고리즘으로 최종 학습을 수행하고 테스트 데이터를 기반으로 다시 최종 예측을 수행
(개별 모델의 예측된 데이터 세트를 다시 기반으로 하여 학습하고 예측하는 방식을 메타 모델이라함)

** 필요한 두 가지 모델
1) 개별적인 기반 모델
2) 개별 기반 모델의 예측 데이터를 학습 데이터로 만들어서 학습하는 최종 메타 모델
**핵심!!
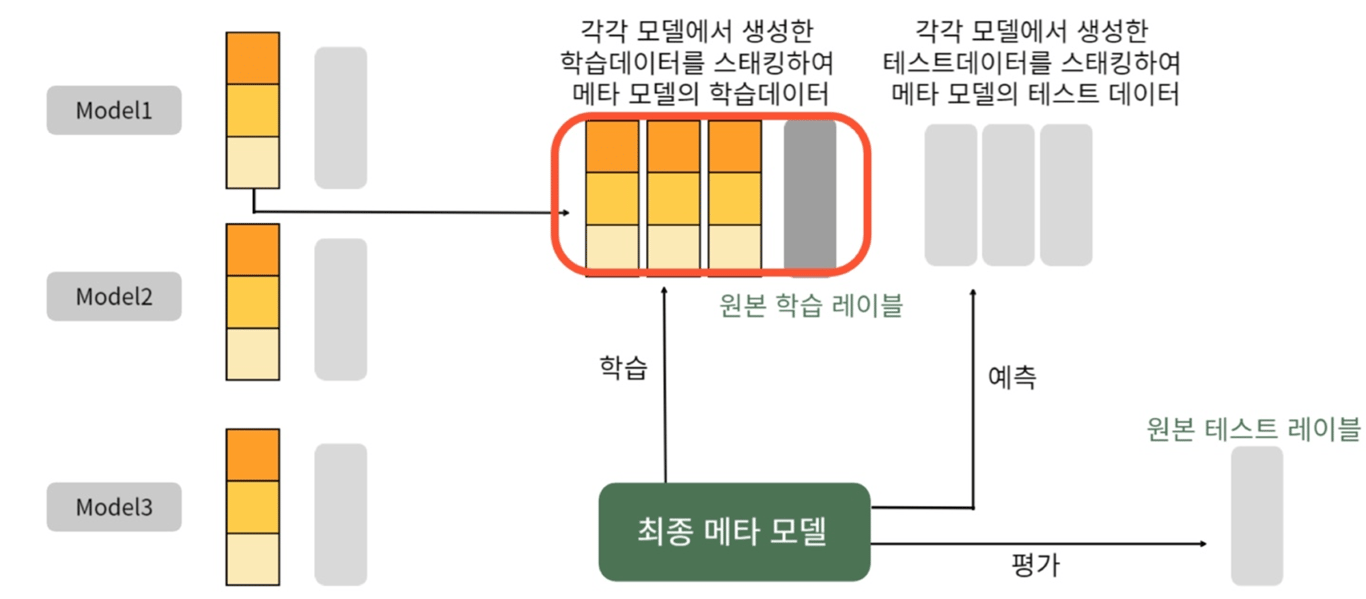
여러 개별 모델의 예측 데이터를 각각 스태킹 형태로 결합해 최종 메타 모델의 학습용 피처 데이터 세트와 테스트용 피처 데이터 세트를 만드는것

- CV 세트 기반의 스태킹
과적합을 개선하기 위해 최종 메타 모델을 위한 데이터 세트를 만들 때 교차 검증 기반으로 예측된 결과 데이터 세트 이용
위의 스태킹은 마지막에 테스트용 레이블 데이터 세트로 기반으로 학습했기에 과적합 문제가 발생할수도,
개별 모델들이 각각 교차 검증으로 메타 모델을 위한 학습용 스태킹 데이터 생성과 예측을 위한 테스트용 스태킹 데이터를 생성한 뒤 이를 기반으로 메타 모델이 학습과 예측을 수행함.
STEP 1)
각 모델별로 원본 학습/테스트 데이터를 예측한 결과 값을 기반으로 메타 모델을 위한 학습용/테스트용 데이터를 생성함(교차검증을 통해 생성)
(개별 모델에서 수행하는 것이며, 이 로직을 여러 개의 개별 모델에서 동일하게 수행)
** 핵심은!
개별 모델에서 메타 모델인 2차 모델에서 사용될 학습용 데이터와 테스트용 데이터를 교차 검증을 통해서 생성하는 것.
STEP 2)
개별 모델들이 생성한 학습용, 테스트용 데이터를 모두 스태킹 형태로 합쳐서 메타 모델이 학습, 예측할 최종 학습용 데이터 세트를 생성.
메타 모델은 최종적으로 생성된 학습 데이터 세트와 원본 학습 데이터의 레이블 데이터를 기반으로 학습한 뒤, 최종적으로 생성된 테스트 데이터 세트를 예측하고, 원본 테스트 데이터의 레이블 데이터를 기반으로 평가
STEP 1)
학습데이터를 n개의 폴드로 나눔.
1️⃣ 2개의 폴드는 학습을 위한 데이터 폴드로, 나머지 1개는 검증을 위한 폴드로 나눔.
이렇게 2개의 폴드로 나뉜 학습 데이터를 기반으로 개별 모델을 학습시킴.
2️⃣ 이렇게 학습된 개별 모델은 검증 폴드 1개 데이터로 예측하고 그 결과를 저장함.
이러한 로직을 3번 반복하면서 학습 데이터와 검증 데이터를 변경해가면서 학습 후 예측 결과를 별도로 저장함.
이렇게 만들어진 예측 데이터는 메타 모델을 학습시키는 학습 데이터로 사용됨.

3️⃣ 2개의 학습 폴드 데이터로 학습된 개별 모델은 원본 테스트 데이터를 예측하여 예측값을 생성함.
마찬가지로 이러한 로직을 3번 반복하면서 이 예측값을 평균으로 최종 결괏값을 생성하고 이를 메타 모델을 위한 테스트 데이터로 사용

STEP 2)
- 각 모델들이 STEP 1으로 생성한 학습과 테스트 데이터를 모두 합쳐서 최종적으로 메타 모델이 사용할 학습 데이터와 테스트 데이터를 생성하기만 하면 됨.
- 최종 테스트 데이터를 사용하여 예측을 수행함.
- 최종 예측 결과를 원본 테스트 데이터의 레이블과 비교평가
'Machine Learning > 분류' 카테고리의 다른 글
| [파이썬 머신러닝 가이드] 분류 - 베이지안 최적화 기반의 HyperOpt를 이용한 하이퍼 파라미터 튜닝 (2) | 2023.12.22 |
|---|---|
| [파이썬 머신러닝 가이드] 분류 - LightGBM (0) | 2023.12.22 |
| [파이썬 머신러닝 가이드] 분류 - XGBoost (0) | 2023.12.22 |
| [파이썬 머신러닝 가이드] 분류 - GBM (0) | 2023.12.22 |
| [파이썬 머신러닝 가이드] 분류 - Random Forest (1) | 2023.12.22 |