

K-Means 알고리즘 이해
: 군집화에서 가장 일반적으로 사용되는 알고리즘으로, 군집 중심(centroid) 라는 특정한 임의의 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택하는 군집화 기법



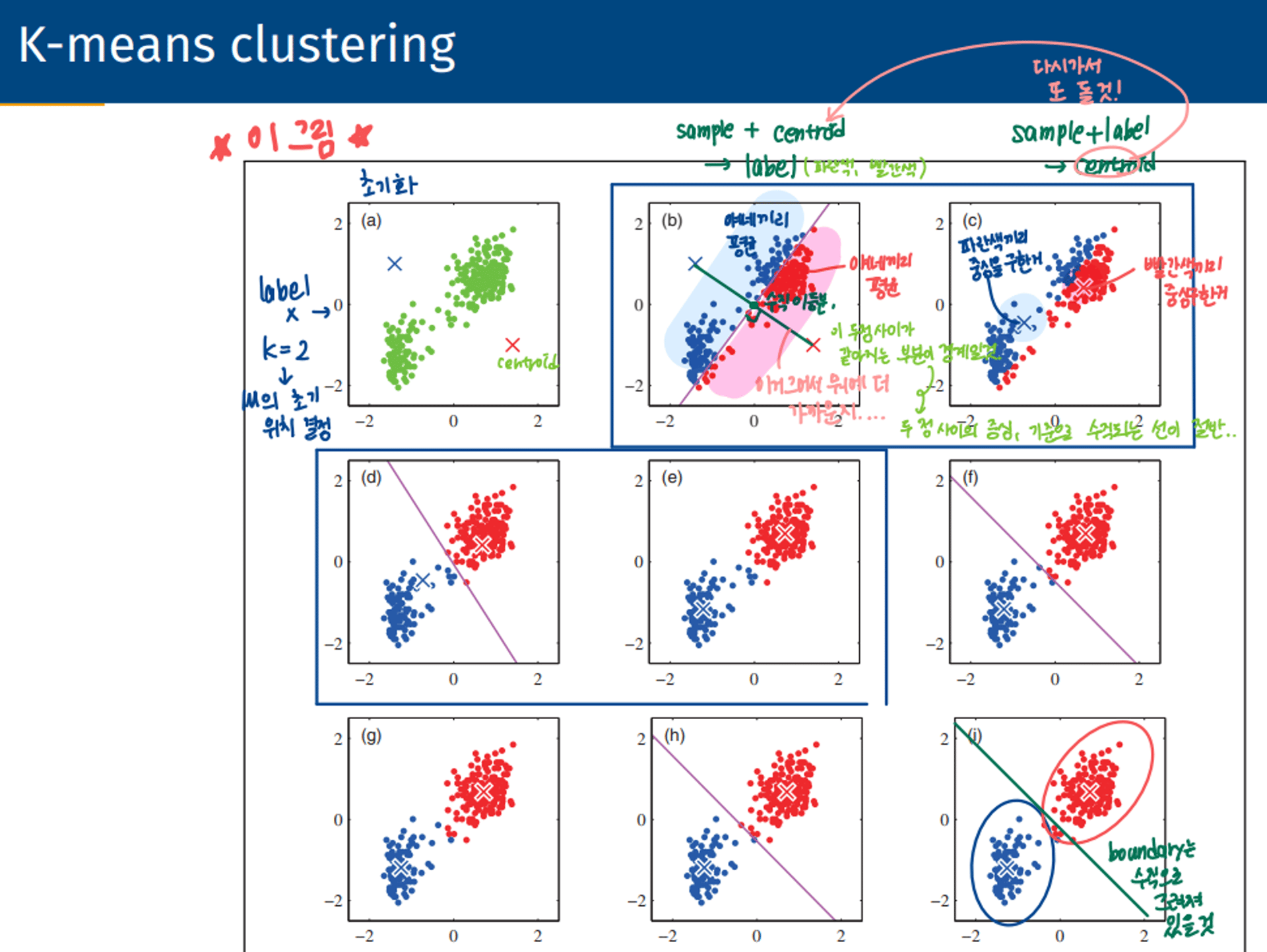
① 먼저 군집화의 기준이 되는 중심을 구성하려는 군집화 개수만큼 임의의 위치에 가져다 놓는다. 전체 데이터를 2개로 군집화하려면 2개의 중심을 임의의 위치에 가져다 놓는 것이다.
② 각 데이터는 가장 가까운 곳에 위치한 중심점에 소속된다. 위 그림에서는 A,B 데이터가 같은 중심점에 소속되며, C, E, F 데이터가 같은 중심점에 소속된다.
③ 이렇게 소속이 결정되면 군집 중심점을 소속된 데이터의 평균 중심으로 이동한다. 위 그림에서는 A, B 데이터 포인트의 평균 위치로 중심점이 이동했고, 다른 중심점 역시 C, E, F 데이터 포인트의 평균 위치로 이동했다.
④ 중심점이 이동했기 때문에 각 데이터는 기존에 속한 중심점보다 더 가까운 중심점이 있다면 해당 중심점으로 다시 소속을 변경한다. 위 그림에서는 C 데이터가 기존의 중심점보다 더 가까운 중심점으로 변경되었다.
⑤ 다시 중심을 소속된 데이터의 평균 중심으로 이동한다. 위 그림에서는 데이터 C가 중심 소속이 변경되면서 두 개의 중심이 모두 이동한다.
⑥ 중심점을 이동했는데 데이터의 중심점 소속 변경이 없으면 군집화를 종료한다. 그렇지 않으면 다시 4번 과정을 거쳐서 소속을 변경하고 이 과정을 반복한다.




즉, 주어진 sample과 주어진 centroid로 label을 구하고, 주어진 sample과 주어진 라벨로 centroid(중심)을 갱신해나가는 과정을 반복하면 점점 데이터들 중심으로 centroid가 움직일 것.
cost J = 각 sample에서 각각 제일 가까운 M까지 거리의 제곱의 합 → 이걸 min 하게 되면 중심이 sample들 중심(M)으로 이동해서 cost 작아짐
K- 평균의 장점
- 일반적인 군집화에서 가장 많이 활용되는 알고리즘
- 알고리즘이 쉽고 간결함
K- 평균의 단점
- 거리 기반 알고리즘으로 속성의 개수가 매우 많을 경우 군집화 정확도가 떨어짐 (이를 위해 PCA로 차원 감소를 적용해야 할 수도 있음)
- 반복을 수행하는데, 반복 횟수가 많을 경우 수행 시간이 매우 느려짐
- 몇 개의 군집(cluster)을 선택해야 할지 가이드하기 어려움


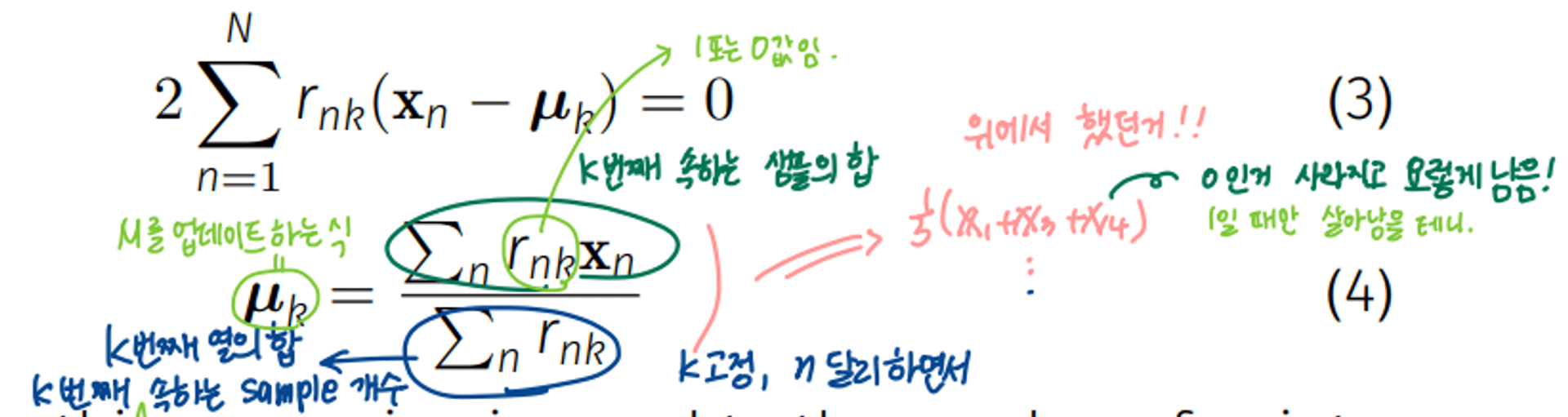
여기서 rnk는 one-of K coding 했을 때의 label임. 그래서 false여서 0인것들은 계산할 때 사라짐.

- M을 업데이트하는 식
- 사이킷런 KMeans 클래스 소개
- 주요 파라미터
- n_clusters : 군집화할 개수, 군집 중심점의 개수
- init : 초기에 군집 중심점의 좌표를 설정할 방식을 말하며 보통은 임의의 중심을 설정하지 않고 일반적으로 k-means++방식으로 최초 설정
- max_iter : 최대 반복 횟수, 이 횟수 이전에 모든 데이터의 중심점 이동이 없으면 종료함.
- 주요 속성 정보
- labels_ :각 데이터 포인트가 속한 군집 중심점 레이블
- cluster_centers_ : 각 군집 중심점 좌표(shape는 [군집 개수, 피처 개수]), 이를 이용하면 군집 중심점 좌표가 어디인지 시각화할 수 있음.
- 주요 파라미터
- 군집화 알고리즘 테스트를 위한 데이터 생성 (여러 개의 클래스에 해당하는 데이터 세트를 만드는데, 하나의 클래스에 여러 개의 군집이 분포될 수 있게 데이터 생성)
- make_blobs() : 개별 군집의 중심점과 표준편차제어기능이 추가되어 있음
- make_classification() : 노이즈를 포함한 데이터를 만드는 데 유용하게 사용 가능
X, y = make_blobs(n_samples=200, n_features=2, centers=3, random_state=0)
#결과 -> 200개의 레코드와 2개의 피처가 3개의 군집화 기반 분포도를 가진 피처 데이터 세트 X와, 동시에 3개의 군집화 값을 가진 타깃 데이터 세트 y 반환'Machine Learning > 군집화' 카테고리의 다른 글
| [파이썬 머신러닝 가이드] 군집화 - DBSCAN, 군집화 실습(고객 세그먼테이션) (2) | 2023.12.26 |
|---|---|
| [파이썬 머신러닝 가이드] 군집화 - GMM(Gaussian Mixture Model) (2) | 2023.12.26 |
| [파이썬 머신러닝 가이드] 군집화 - 평균 이동 (2) | 2023.12.26 |
| [파이썬 머신러닝 가이드] 군집화 - 군집 평가 (Clustering Evaluation) (0) | 2023.12.25 |