

목차
Convolutional Neural Network
- CNN 역시 변형된 backpropagation 알고리즘으로 학습
- 최소한의 전처리 만으로도 픽셀로부터 시각적 패턴을 인식
1) CNN 기본 구성요소
** Stride
stride는 필터를 얼마만큼 움직여주는가를 의미.
기본적으로 stride는 1이지만, 테스트에 따라서 stride를 1 이상의 값으로 설정할 수도 있음
**stride와 padding을 적용했을 때의 최종
-입력데이터 높이 : H
-입력 데이터 너비 : W
-필터 높이 : FH
-필터 너비 : FW
-Stride 크기 : S
-패딩 사이즈 : P
-output 너비 = (W + 2P - FW) / S +1
-output 높이 = (H + 2P - FH) / S +1
** Pooling Layer
-Convolution Layer에서 얻어진 출력값에서 특징을 뽑아내는 과정
→ 일반적으로 데이터 차원수를 줄이는 등의 작업은 데이터의 특징을 추출하는 과정으로 볼 수 있음.
-Pooling 사이즈는 입력 데이터의 배수여야하며, 정사각형 사이즈
-pooling 사이즈가 2X2이면, 2X2마다 가장 큰 값을 취하는 걸 max pooling, 평균값을 취하는 걸 average pooling이라고 함,



**Flatten(Vectorization)
- CNN 네트워크의 마지막에는 클래스 분류를 위해, fully connected layer에 전달함,
- 전달하기 위해, 1차원 텐서로 만들어줘야함, 이를 flatten이라고함.
**fully-connected layer
마지막으로 하나 이상의 FC layer에 적용시켜주고, 클래스 분류를 위해 log softmax 등의 activation 함수를 적용해주어, 최종 예측값 계산
** Convolution Layer는 입력 데이터에 필터를 적용 후, activation 함수를 적용함.

→ 하나의 이미지의 여러 convolution layer를 통과시켜, 다양한 feature map을 추출함,

*convolution은 입력 이미지의 다른 부분들에 존재하는 동일한 특징들을 찾아냄.
2) Pytorch와 CNN
- Convolution Layers와 Pytorch
- Conv1d (1차원 입력 데이터를 위한 Convolution Layer, 일반적으로 Text-CNN에서 많이 사용)
- Conv2d (2차원 입력 데이터를 위한 Convolution Layer, 일반적으로 이미지 분류에서 많이 사용)
- Conv3d (3차원 입력 데이터를 위한 Convolution Layer)
- Conv2d → n1개의 입력채널을 가지고 n2개의 출력채널을 생성하는 conv 레이어 형성
Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')ex) nn.Conv2d(1,2,3) → 입력 채널 수 1, 출력 채널수 2, 커널 3x3
** 중요한 건,
채널 수랑, 입력 데이터의 행,열 크기(이미지 크기)는 상관 없는 것
→ 모델에서 원하는 채널수로 모듈 만들어 두면, 나중에 데이터 들어오는 입력대로 정해진 입출력 채널수를 가진 모델에 적용할 수 있는 것.
- 주요 옵션
- in_channels (int) – 입력 채널 수 (흑백 이미지일 경우는 1, RGB 값을 가진 이미지일 경우 3)
- out_channels (int) – 출력 채널 수
- kernel_size (int or tuple) – 커널(필터) 사이즈 (int 또는 튜플로 적용 가능) -> 보통 가로 세로 동일한 경우가 많지. 3x3 등등 -> 그럴 땐 3 이렇게 숫자만 넣어둠. 다르면 튜플로 (2,3) 이렇게 넣어줌.
- stride (int or tuple, optional) – stride 사이즈 (Default: 1)
- padding (int, tuple or str, optional) – padding 사이즈 (Default: 0)
- padding_mode (string, optional) – padding mode (Default: 'zeros')
- 이외에도 'zeros', 'reflect', 'replicate' or 'circular' 등 버전 업데이트마다 지속 추가중
- dilation (int or tuple, optional) - 커널 사이 간격 사이즈 (Default :1)
- Shape 이해
- Input Tensor: (𝑁,𝐶𝑖𝑛,𝐻𝑖𝑛,𝑊𝑖𝑛)
- N: batch 사이즈
- 𝐶𝑖𝑛: in_channels (입력 채널 수) 와 일치해야 함
- 𝐻𝑖𝑛: 2D Input Tensor 의 높이
- 𝑊𝑖𝑛: 2D Input Tensor 의 너비
- Input Tensor: (𝑁,𝐶𝑖𝑛,𝐻𝑖𝑛,𝑊𝑖𝑛)
ex) input = torch.randn(16, 3, 32, 32) 라면
batch_size 16, 입력 채널 갯수 3개, 2D 높이(행) 5, 2D 너비(열) 5
→ 입력 이미지의 크기가 16개의 샘플로 이루어진 RGB의 32 x 32 이미지
- Output Tensor: (𝑁,𝐶𝑜𝑢𝑡,𝐻𝑜𝑢𝑡,𝑊𝑜𝑢𝑡)
- N: batch 사이즈
- 𝐶𝑜𝑢𝑡: out_channels (출력 채널 수) 와 일치해야 함
- 𝐻𝑜𝑢𝑡: (𝐻𝑖𝑛+2×𝑝𝑎𝑑𝑑𝑖𝑛𝑔[0]−𝑑𝑖𝑙𝑎𝑡𝑖𝑜𝑛[0]×(𝑘𝑒𝑟𝑛𝑒𝑙𝑠𝑖𝑧𝑒[0]−1)−1) / 𝑠𝑡𝑟𝑖𝑑𝑒[0]+1
- 𝑊𝑜𝑢𝑡: (𝑊𝑖𝑛+2×𝑝𝑎𝑑𝑑𝑖𝑛𝑔[1]−𝑑𝑖𝑙𝑎𝑡𝑖𝑜𝑛[1]×(𝑘𝑒𝑟𝑛𝑒𝑙𝑠𝑖𝑧𝑒[1]−1)−1) / 𝑠𝑡𝑟𝑖𝑑𝑒[1]+1
- stride 는 일반적으로는 int 로 하나의 값으로 지정가능하지만,
- 다양한 CNN 알고리즘 중에는 너비, 높이에서의 padding, stride 를 달리할 수 있고 (dilation 도 마찬가지임), 이를 (stride[0], stride[1]) 의 예와 같이 튜플 형태로 적용도 가능함
- shape 일반적인 계산
- output 너비 = (입력 데이터 너비 + 2*패딩사이즈 - 필터너비) / stride 크기 +1
- output 높이 = (입력 데이터 높이 + 2*패딩사이즈 - 필터 높이) / stride 크기 + 1
- MaxPool2d
MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)ex) nn.MaxPool2d(2)하면 사이즈 2로 나눠주면 되는데, 나눠떨어지지 않으면 뒤에 버리는게 디폴트
- 주요 옵션
- kernel_size: 커널 사이즈 (=pooling_size, pooling size가 2 -> 2x2이면, 2x2 마다 가장 큰 값을 취하는 것을 max pooling, 평균값을 취하는 것을 average pooling이라 함)
- stride: stride 사이즈 (Default: kernel_size)
- padding: padding 사이즈
- dilation: 커널 사이 간격 사이즈
- ceil_mode: True 일 경우, 출력 shape 계산시, 나누어 떨어지지 않을 경우 ceil 사용 (디폴트: floor)
- 참고: floor (무조건 내림, 예: floor(3.7) = 3)
- 참고: ceil (무조건 올림, 예: ceil(3.1) = 4)
- 모델 정의
- Convolution Layer 는 입력 데이터에 필터(커널) 적용 후, activation 함수 적용한 Layer 를 의미함
- Convolution Layer 는 입력 데이터에 필터(커널) 적용을 위한 전용 클래스 제공 (nn.Conv2d)
- 이후에 Activation 함수 적용 (예: nn.LeakyReLU(0.1))
- 이후에 Batch Nomalization, Dropout 등 regularization 을 적용할 수도 있음 (옵션)
- 이후에 Pooling 적용(예: nn.MaxPool2d)
- BatchNorm1d() 과 BatchNorm2d()
- BatchNorm1d(C) 는 Input과 Output이 (N, C) 또는 (N, C, L)의 형태
- N은 Batch 크기, C는 Channel, L은 Length
- BatchNorm2d(C) 는 Input과 Output이 (N, C, H, W)의 형태
- N은 Batch 크기, C는 Channel, H는 height, W는 width
- 인자로 Output Channel 수를 넣으면 되며, Conv2d() 에서는 BatchNorm2d() 를 사용해야 함
- BatchNorm1d(C) 는 Input과 Output이 (N, C) 또는 (N, C, L)의 형태
- Convolution Layer 는 입력 데이터에 필터(커널) 적용 후, activation 함수 적용한 Layer 를 의미함
- 기본 신경망 모델 코드 작성법
- 신경망 모델 클래스 만들고, nn.Module 상속받음
- __ init__에서 신경망 계층 초기화
- forward 메소드에서 입력 데이터에 대한 연산 정의

3) CNN 모델 구성
- 다음 세트로 하나의 Convolution Layer + Pooling Layer 를 구성하고, 여러 세트로 구축
- 보통 Convolution Layer + Pooling Layer 의 출력 채널을 늘리는 방식으로 여러 세트 구축
nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1), nn.LeakyReLU(0.1), nn.BatchNorm2d(32), nn.MaxPool2d(2), nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1), nn.LeakyReLU(0.1), nn.BatchNorm2d(64), nn.MaxPool2d(2), - Flatten → view를 통해 flatten 하는 건 보통 forward 메소드(함수)에서 진행
- 텐서.view(텐서.size(0), -1) 로 Flatten
self.conv_layer.view(out.size(0),-1)
*파이토치 view 함수와 reshape 함수 비교
-파이토치에서 텐서의 차원 변환을 할 때
두 함수 모두 input으로 원하는 차원의 형태를 바로 적어주면 됨
import torch
x = torch.arange(12)
x.reshape(3, 4)
# tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
x.view(2, 6)
# tensor([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11]])
torch.view와 torch.reshape의 가장 큰 차이는 contiguous 속성을 만족하지 않는 텐서에 적용이 가능하느냐 여부. view는 contiguous 속성이 만족되지 않는 경우 일부 사용이 제한될 수 있음.
*contiguous란?
a = torch.randn(3, 4)
a.transpose_(0, 1)
b = torch.randn(4, 3)
→ 두 tensor는 모두 (4, 3) shape
a,b 텐서에 저장된 값들의 메모리 주소를 axis 방향(오른쪽 방향 우선) 순서로 불러와보면,
- a 텐서 메모리 주소 예시
for i in range(4):
for j in range(3):
print(a[i][j].data_ptr())
'''94418119497152 94418119497168 94418119497184 94418119497156 94418119497172 94418119497188 94418119497160 94418119497176 94418119497192 94418119497164 94418119497180 94418119497196'
- b 텐서 메모리 주소 예시
for i in range(4):
for j in range(3):
print(b[i][j].data_ptr())94418119613696 94418119613700 94418119613704 94418119613708 94418119613712 94418119613716 94418119613720 94418119613724 94418119613728 94418119613732 94418119613736 94418119613740
각 데이터의 타입인 torch.float32 자료형은 4바이트이므로, 메모리 1칸 당 주소 값이 4씩 증가함.
그런데 자세히 보면 b는 한 줄에 4씩 값이 증가하고 있지만, a는 그렇지 않은 상황임을 알 수 있음.

즉, b는 axis = 0인 오른쪽 방향으로 자료가 순서대로 저장됨에 비해, a는 transpose 연산을 거치며 axis = 1인 아래 방향으로 자료가 저장되고 있었음.
여기서, b처럼 axis 순서대로 자료가 저장된 상태를 contiguous = True 상태라고 부르며, a같이 자료 저장 순서가 원래 방향과 어긋난 경우를 contiguous = False 상태라고 함.
각 텐서에 stride() 메소드를 호출하여 데이터의 저장 방향을 조회할 수 있음. 또한, is_contiguous() 메소드로 contiguous = True 여부도 쉽게 파악할 수 있음.
a.stride()
# (1, 4)
b.stride()
# (3, 1)a.is_contiguous()
# False
b.is_contiguous()
# True여기에서 a.stride() 결과가 (1, 4)라는 것은 a[0][0] -> a[1][0]으로 증가할 때는 자료 1개 만큼의 메모리 주소가 이동되고, a[0][0] -> a[0][1]로 증가할 때는 자료 4개 만큼의 메모리 주소가 바뀐다는 의미임.
- 바꿔주는 방법
#텐서를 contiguous = True 상태로 변경
a = a.contiguous()
a.is_contiguous()
# True
따라서 차원 변환을 적용하려는 텐서의 상태에 대하여 정확하게 파악하기가 모호한 경우엔, view 대신 reshape 사용 권장
- layer 3개 (1 layer 구성 : conv + activation.f + pooling ) + flatten
conv1 = nn.Sequential (
nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
nn.LeakyReLU(0.1),
nn.BatchNorm2d(32), #인자로 output 채널의 수를 넣으면됨. #여기까지 계산하면 28x28
nn.MaxPool2d(2), # 여기 거치면 14 x 14 (pooling은 그냥 나눠주는 거임.)
# Img = (1, 1, 28, 28)
# Conv = (28 + 2 * 1 - 3) + 1 = 27 + 1 = 28, (1, 32, 28, 28)
# MaxPool = 28 / 2 = 14, (1, 32, 14, 14)
nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
nn.LeakyReLU(0.1),
nn.BatchNorm2d(64),
nn.MaxPool2d(2),
# Conv = (14 + 2 * 1 - 3) + 1 = 13 + 1 = 14, (1, 64, 14, 14)
# MaxPool = 14 / 2 = 7, (1, 64, 7, 7)
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.LeakyReLU(0.1),
nn.BatchNorm2d(128),
nn.MaxPool2d(2)
# Conv = (7 + 2 * 1 - 3) + 1 = 6 + 1 = 7, (1, 128, 7, 7)
# MaxPool = 7 / 2 = 7, (1, 128, 3, 3)
)
input1 = torch.Tensor(1, 1, 28, 28)
out1 = conv1(input1)
out2 = out1.view(out1.size(0), -1) #shape을 변경하는 view 함수. 이렇게하면 하나의 차원으로 flatten 됨. / size(0)은 batch size 1인거 그대로 가져오고, 나머지는 -1 씀으로써 하나로 알아서 합쳐주기.
print (out1.shape, out2.shape, 128 * 3 * 3)
#torch.Size([1, 128, 3, 3]) torch.Size([1, 1152]) 1152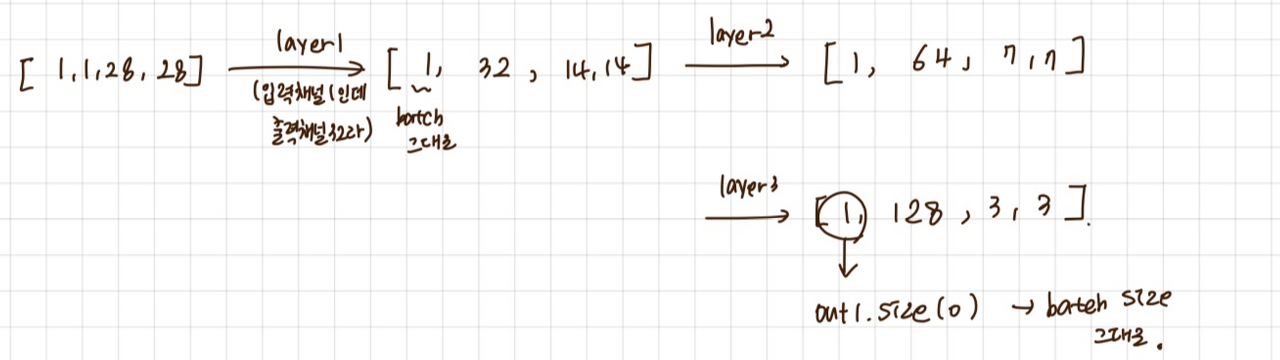
3. 여러 Fully-Connected Layer 로 구성
- Flatten 한 입력을 받아서, 최종 Multi-Class 갯수만큼 출력
- Multi-Class 일 경우, nn.LogSoftmax() 로 최종 결과값 출력
nn.Linear(3* 3* 128, 128), #피처맵을 일렬로 펴는 과정, 여기 적혀 있는 숫자들은 다 차원임.
#일렬로 폈을 때 3*3*128 노드, 즉 이걸 입력 벡터로 해서 128개의 히든노드를 가진 히든레이어를 만듦
nn.LeakyReLU(0.1),
nn.BatchNorm2d(128),
nn.Linear(128, 64),
nn.LeakyReLU(0.1),
nn.BatchNorm2d(64),
nn.Linear(64, 10), #여기선 히든레이어 64개에서 출력층에는 10가지 클래스를 구별하는 모델이니까 10개 노드로 최종 출력이 되도록
nn.LogSoftmax(dim=-1)
**** nn.Linear 짚고 넘어가기
y = torch.matmul(X, self.w) + self.b
*이걸 하나로 만든 게 nn.linear
ex) nn.Linear(4,3)
→ 입력 4, 출력 3차원의 linear layer 함수 구현하는 객체
입력 차원 : 3 x 3 x 128
출력 차원 : 128
f(x) = x * W + b라 하면,
W = (3 x 3 x 128(입력쪽 갯수), 128(출력쪽 갯수))임.

=> linear 가 여러개 있는건 최종 목표까지 여러번 linear 과정 거치는 것.
- Conv + Pool + linear


class CNNModel(nn.Module):
def __init__(self):
super().__init__()
self.conv_layers = nn.Sequential (
nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
nn.LeakyReLU(0.1),
nn.BatchNorm2d(32),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
nn.LeakyReLU(0.1),
nn.BatchNorm2d(64),
nn.MaxPool2d(2),
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.LeakyReLU(0.1),
nn.BatchNorm2d(128),
nn.MaxPool2d(2)
)
#여기서 flatten까지 된 것. flatten 한게 없는데 왜? -> 밑에 forward 메소드에서 x에 view해서 flatten해서 그런 듯
self.linear_layers = nn.Sequential #또다른 객체를 만들어서 linear layer만 넣음.
nn.Linear(3 * 3 * 128, 128), #입력의 수 맞춰줘야해서. flatten해서 들어옴.
#여기 사이즈 안맞으면 에러남. 위 객체까지가 위에 만든, flatten 하기까지 layer랑 정규화랑 pooling 통과시켜서 만든거.
#위 객체 통해서 나온 결과는 [1, 1152] 였으니까 여기서 출력이었던 1152, 즉 3*3*128이 여기선 입력이 된거임.
nn.LeakyReLU(0.1),
nn.BatchNorm1d(128), # Linear Layer 이므로, BatchNorm1d() 사용해야 함
nn.Linear(128, 64),
nn.LeakyReLU(0.1),
nn.BatchNorm1d(64), # Linear Layer 이므로, BatchNorm1d() 사용해야 함
nn.Linear(64, 10), #마지막엔 class 10개를 예측하게끔.
nn.LogSoftmax(dim=-1) #multiclass classification에선 맨 끝에 logsoftmax나 softmax를 씀
)
def forward(self, x):
x = self.conv_layers(x) # Conv + Pool
x = x.view(x.size(0), -1) # Flatten
#shape을 변경하는 view 함수. 이렇게하면 하나의 차원으로 flatten 됨. / size(0)은 batch size 1인거 그대로 가져오고, 나머지는 -1 씀으로써 하나로 알아서 합쳐주기.
x = self.linear_layers(x) # Classification
return x
'Deep Learning & AI > CV' 카테고리의 다른 글
| [VGG] 졸음운전 분류 프로젝트 (4) | 2024.03.11 |
|---|---|
| [CNN] 졸음운전 분류 프로젝트 (0) | 2024.03.04 |
| [CNN] 전이 학습 - 특성 추출 기법 (1) | 2024.01.01 |
| [CNN] Fashion MNIST 데이터로 CNN 실습하기 (1) | 2023.12.29 |
| [CNN] Image Convolution (1) | 2023.12.29 |