

전 게시물에서 CNN과 VGG를 활용해서 졸음운전을 분류하는 프로젝트를 정리해보았는데, 이번엔 이어서 ResNet을 사용해서 진행해본 부분을 정리해보겠다.
[CNN] 졸음운전 분류 프로젝트
ION Lab에서 CNN을 활용하여 졸음운전을 분류해보는 프로젝트를 진행해보았다. 운전자의 특징 변화를 측정함으로써 졸음여부를 판단하는 방법으로 CNN 기반 모델이 운전자의 '눈'을 인식하여 졸음
y8jinn.tistory.com
[VGG] 졸음운전 분류 프로젝트
전 게시물에서 CNN을 활용해서 졸음운전을 분류하는 프로젝트를 정리해보았는데, 이번엔 이어서 VGG와 ResNet을 사용해서 진행해본 부분을 정리해보겠다. https://y8jinn.tistory.com/65 VGG - 적절한 kernel(=f
y8jinn.tistory.com
ResNet
딥러닝 모델은 레이어를 깊게 쌓을수록 성능이 좋아질 여지가 생기지만, 문제는 레이어를 깊게 쌓을 수록 기울기 소실(특히 tanh나 시그모이드를 쓰면 입력의 절대값이 클 경우 시그모이드 함수의 출력값이 0 또는 1에 수렴하면서 기울기가 0에 가까워짐. 그래서 역전파 과정에서 전파시킬 기울기가 점차 사라져서 입력층 방향으로 갈수록 제대로 역전파가 되지 않는 문제)과 기울기 폭발이 쉽게 나타나서 모델을 학습시키기 쉽지 않음
→ 레이어가 깊어졌음에도 성능은 오히려 하락하는 degradation 문제 발생

← VGGNet 모델처럼 단순히 conv layer를 적층하는 기본적인 구조를 갖는 CNN 아키텍처로 20개의 레이어를 사용했을 때와 56개의 레이어를 사용했을 때 비교한 결과
좌측이 학습에러율, 우측이 테스트 에러율인데 둘다 56개 레이어 사용했을 때 성능이 더 악화된 것을 확인할 수 있음
- ResNet 모델의 핵심은 residual learning !!
residual learning은 conv layer의 input에 해당하는 x값을 conv layer의 output에 다시 더해줌으로써, conv layer가 input 값과 output 사이의 차이(잔차, residual)를 학습하는 데만 집중할 수 있도록 하는 기법.
residual learning을 위해 input 값을 output 값에 더하는 과정을 shortcut connection 또는 skip connection으로 표현하며, 이렇게 residual learning을 하도록 구성된 하나의 단위를 residual block이라고 부름.

** 특정 위치에서 입력이 들어왔을 때 합성곱 연산을 통과한 결과와 입력으로 들어온 결과 두가지를 더해서 다음 레이어에 전달하는 것이 ResNet의 핵심! **
잔차 학습은 이전 단계에서 뽑았던 특성들을 변형시키지 않고, 그대로 다음 단계로 전달하여 더해주기 때문에 앞에서 학습한 low-level 특징과 뒤에서 학습한 high-level 특징을 모두 다음 block(단계)로 전달할 수 있다는 장점을 가지고 있음.
VGGNet-GoogleNet-ResNet 순서에서, 전에 GoogleNet의 경우, Neural Network 의 Vanishing Gradient 문제를 해결하기 위해 Auxilary Classifier를 사용했음. 하지만 ResNet의 경우 더하기 연산은 그냥 기울기가 1이기 때문에 역전파 시 loss가 줄지 않고, (tanh은 곱할수록 줄어들었음) 모델 앞까지 잘 전파가 된다는 특징이 있어서 별도로 Auxilary Classifier 필요하지 않음.
** 이 때, input값과 output 값을 더하려면, 데이터의 shape도 같아야 함. 가로, 세로 영역은 3x3 크기의 kernel을 사용하니 패딩 값을 주어 크기를 그대로 유지할 수 있지만, input 값의 채널 수와 output 값의 채널 수가 다르면 문제가 됨.
→ 이를 해결하기 위해, input 값의 채널 수(차원)와 output 값의 채널 수(차원)가 같을 때는 input 값을 output 값에 그대로 더하는, 일명 identity shortcut connection을 수행하되,
채널 수가 서로 다를 때는 shortcut connection 부분에서 별도로 1x1 크기의 kernel을 가진 conv layer를 사용하여 채널 수를 조정하는 projection shortcut connection을 수행하여 데이터의 shape을 맞춰줌.

실선 - feature map의 dimension이 바뀌지 않아 그냥 더해주는 경우. 점선은 입력단과 출력단의 dimension의 차이로 인해 이를 맞춰줄 수 있는 테크닉이 추가적으로 더해진 경우.
- shortcut 사용방법에 따른 성능 비교

-(A) Increasing Dimension에 Zero Padding을 활용한 Shortcut을 사용
-(B) Increasing Dimension에 Projection Shortcut을 사용 → 뒤에 나오는 bottleneck block은 이거 적용
-(C) 모든 Shortcut을 Projection Shortcut으로 대체하여 사용
3가지 옵션 모두 plain network보다 성능이 좋으며, A<B<C 순으로 성능이 좋음.
논문에서는 B가 A보다 나은 이유를 A의 zero-padding 과정에 residual learning이 없기 때문이라고 함.
그리고 C가 B보다 좋은 이유로는 extra parameters가 더 많기 때문에.
- ResNet 종류
ResNet-18, ResNet-34, ResNet-50, ResNet-101, ResNet-152 총 5가지 모델임.
이 중, 레이어 수가 50개 이상인 ResNet50부터는 파라미터 수를 제어하기 위해서 bottleneck 구조의 residual block이 사용됨. → 1x1 크기의 kernel을 가진 conv layer를 통해 채널 수를 줄이는 전략을 사용하여 파라미터 수를 통제함.

논문에선, layer가 깊어지면 training time이 증가하는 것을 발견하였고, 이를 고려하여 residual block을 아래와 같이 1x1 convolution을 활용하여 개선한 bottleneck block을 제안함.

💡 Plain Network은 다음과 같은 규칙에 따라 만들어졌습니다:
- 같은 크기의 output feature map을 갖고 있다면, 같은 수의 filters를 갖도록 합니다.
- 만약 feature map size가 반으로 줄어들었다면, time-complexity를 유지하기 위해 filters의 수는 두 배가 되도록 합니다.
- Downsampling을 하기 위해서 stride가 2인 conv layers를 통과시켜줍니다.
- 1x1 convolution의 경우, 동일한 사이즈의 feature map을 유지하기 위해 별도의 padding이 필요없습니다.
하지만, 3x3 convolution의 경우, 동일한 사이즈의 feature map을 유지하기 위해 size 1의 padding이 필요하게 됩니다.
- Network의 마지막 단에는 Global Average Pooling(GAP)를 수행하며, ImageNet Classification을 목적으로 하기 때문에 1000-way-fully-connected layer로 이루어져 있습니다.
ResNet이 위 plain network와 다른 점은 각각의 block 들이 끝날때마다 shortcut connection 추가된다는 점.
- 배치 정규화 사용
ResNet 모델에서 또하나 주목할만한 점은 배치 정규화 사용했다는 것.
ResNet 논문에서는 conv layer 직후에 batch normalization layer를 두고, 그 뒤에 ReLU 함수를 배치해서 사용함.
배치 정규화는 gradient vanishing과 gradient exploding 문제를 해결하고, overfitting을 줄이는데 효과적임.
배치 정규화 레이어는 미니 배치 단위로 평균과 분산을 계산하여 정규화를 수행하는데, 모델 학습 과정에서 scale 값과 shift 값을 학습하여 정규화에 함께 사용함.
즉, 배치 정규화 레이어는 미니 배치 단위로 평균과 분산을 통해 표준화를 한 뒤, 그 값에 학습된 scale 값을 곱하고 학습된 shift값을 더하는 방식으로 정규화를 수행하는 레이어임.
- ResNet 모델 구축
ResNet-18과 유사한 구조(같은 규모와 구조)인데, 그것보다 더 간단한 구조임.
torchvision.models.resnet을 통해 ResNet(18,34,50,101,152) 을 만들 수 있지만, 이는 3x224x224 입력을 기준으로 만들도록 되어있음
→ 간단한 구조로 만듦
ResNet18과 유사하지만 더 간단하며 작은 데이터셋이나 모델 크기에 적합한 구조를 만듦.
유사점
- residual blocks 사용 : 두 모델 모두 residual block 구조를 사용함. (네트워크 깊이를 증가시키는 데 도움되며, gradient vanishing 문제 해결)
- pre-activation 구조 : 두 모델 모두 residual block 내에서 BatchNorm-ReLU-Conv 순서 사용함.(pre-activation ResNet에서 사용되는 방법론)
- 마지막 레이어 이전에 global average pooling 사용 → 마지막 conv layer의 피처맵을 각각의 채널에 대해 평균을 구함으로써 공간적인 정보를 버리고 채널의 중요도 유지. 이후 이 평균 값들을 통해 각 클래스에 대한 확률을 예측할 수 있는 fully connected layer로 전달
- 마지막 fully connected layer : 마지막에 fully connected layer가 있고, 그 뒤에 log softmax 사용
차이점
- 깊이와 블록 수 : ResNet18은 각 레이어에서 더 많은 residual block 사용함.
- layer의 갯수와 구조 : ResNet18에서는 각 레이어마다 더 많은 블록 사용함.
import torch.nn as nn
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(ResidualBlock, self).__init__()
# 3x3 필터를 사용 (너비와 높이(차원)를 줄일 때는 stride 값 조절-> 2로 설정하면 너비와 높이 절반 줄어듦)
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels) # 배치 정규화
self.relu = nn.ReLU(inplace=True)
# 3x3 필터를 사용 (패딩을 1만큼 주기 때문에 너비와 높이가 동일)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels) # 배치 정규화
self.downsample = downsample
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample: # 스킵 연결이 있는 경우, input과 output 데이터 수가 다를 때, 입력을 다운샘플링하여 residual과 out을 더하기 전에 차원을 맞춰줌.
residual = self.downsample(x) #downsample은 stride가 1이 아니라 2가 들어오는 경우를 생각해보면 됨. stride가 2라면 output이 반으로 줄어들게 되는데 residual의 크기는 줄어들지 않았으니까 덧셈이 불가능해짐. 이러한 문제를 해결하기 위해 downsample 사용
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module): # ResNet은 Residual Block(Basic Block)을 여러번 연결하는 방식으로 구현
def __init__(self, block, layers, num_classes=2): #ResNet 구성할 때 layers(block의 갯수)를 입력 받을 수 있음. -> 밑에 resnet 정의할 때 논문처럼 Residual block 2번씩 중첩되어서 사용할 수 있도록 함.
super(ResNet, self).__init__()
self.in_channels = 16
self.conv = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=False) # 하나의 conv 이용해서 dimension 바꿔준 뒤에
self.bn = nn.BatchNorm2d(16)
self.relu = nn.ReLU(inplace=True) # basic block 당 conv layer가 2개씩 들어가 있음.
self.layer1 = self.make_layer(block, 16, layers[0]) # 여기서 연속적으로 residual block 이어붙임. 여기를 3, 64, 128, 256, 512 layer로 쌓으면 논문과 동일한 layer, stride 값은 default로 1
self.layer2 = self.make_layer(block, 32, layers[1], 2) # filter의 개수 증가할 때 stride=2 써서 너비와 높이 줄어들 수 있도록
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1)) # residual block당 conv layer가 2개 들어가있는데, 그걸 2번 연결하니까 layer1이 총 4개의 conv. 여기선 layer 2개만 썼으니 총 8개 conv layer.
self.fc = nn.Linear(32, num_classes) # num_classes 매개변수의 기본 값은 2이므로, 이진분류 수행(명시적으로 지정안하면 기본 값으로 이진 분류 모델 생성)
self.log_softmax = nn.LogSoftmax(dim=-1)
def make_layer(self, block, out_channels, blocks, stride=1): #residual block 레이어 생성
downsample = None # 처음에는 다운샘플링이 없음. (첫번째 conv 연산에서만 너비와 높이가 줄어들 수 있도록)
if (stride != 1) or (self.in_channels != out_channels): # 현재 stride가 1이 아니거나(1 아니면 output값만 달라지니까) input 채널수와 output 채널수가 달라 덧셈이 불가능할 때, downgrade.
downsample = nn.Sequential( #각 residual block 레이어를 생성하고 이를 Sequential 레이어로 묶어 반환함.
nn.Conv2d(self.in_channels, out_channels, kernel_size=1, stride=stride, bias=False), #stride 거쳐서 동일한 차원으로)
nn.BatchNorm2d(out_channels) # 다운샘플링이 필요한 경우, 입력 채널 수와 출력 채널 수를 맞추기 위해 1x1 conv layer와 배치 정규화 레이어로 이루어진 다운샘플링 레이어 생성.
)
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample)) #첫번째 residual block 생성 후 layers 리스트에 추가
self.in_channels = out_channels #다음 블록을 생성할 때 사용할 입력 채널 수 업데이트 함. 현재 블록의 출력 채널 수와 같아짐.
for _ in range(1, blocks): #두 번째 residual block 부터 blocks 개수만큼의 레이어를 생성하기 위해 반복문 설정
layers.append(block(out_channels, out_channels)) #블록 생성하고 layers 리스트에 추가. 입력 채널 수와 출력 채널 수가 동일하므로 다운샘플링 필요 X.
return nn.Sequential(*layers) #*layers는 각 리스트에 있는 residual block 들을 순차적으로 인자로 전달하는걸 의미.
def forward(self, x): #입력 이미지를 받아 모델을 통과시킴. 초기 레이어를 통과시킨 다음,
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
x = self.layer1(x) #make_layer 메서드 사용해서 생성된 residual block 레이어를 통과시킴.
x = self.layer2(x)
x = self.avg_pool(x) #average pooling 적용.
x = x.view(x.size(0), -1)
x = self.fc(x) # fully connected 레이어 거쳐 최종 출력 생성함.
x = self.log_softmax(x)
return x
# ResNet 모델 생성
resnet_model = ResNet(ResidualBlock, [2, 2]) # ResNet18과 유사한 구조로 [2,2]는 block, layers. 두 개의 ResidualBlock과 각 block 에는 2개의 layer.
# 모델 출력 확인
print(resnet_model)ResNet( (conv): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (layer1): Sequential( (0): ResidualBlock( (conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (1): ResidualBlock( (conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer2): Sequential( (0): ResidualBlock( (conv1): Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(16, 32, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): ResidualBlock( (conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (avg_pool): AdaptiveAvgPool2d(output_size=(1, 1)) (fc): Linear(in_features=32, out_features=2, bias=True) (log_softmax): LogSoftmax(dim=-1) )
from timeit import default_timer as timer
from tqdm import tqdm
EPOCHS = 5
batch_size = 50
loss_func = nn.NLLLoss()
optimizer = torch.optim.SGD(resnet_model.parameters(), lr=0.1, momentum = 0.9, weight_decay = 0.0002)
start_time = timer()
model3_res = training(model=resnet_model,
train_dataloader=train_loader,
test_dataloader=test_loader,
optimizer=optimizer,
loss_fn=loss_func,
epochs=EPOCHS)
end_time = timer()
print(f"Total training time: {end_time-start_time:.3f} seconds")
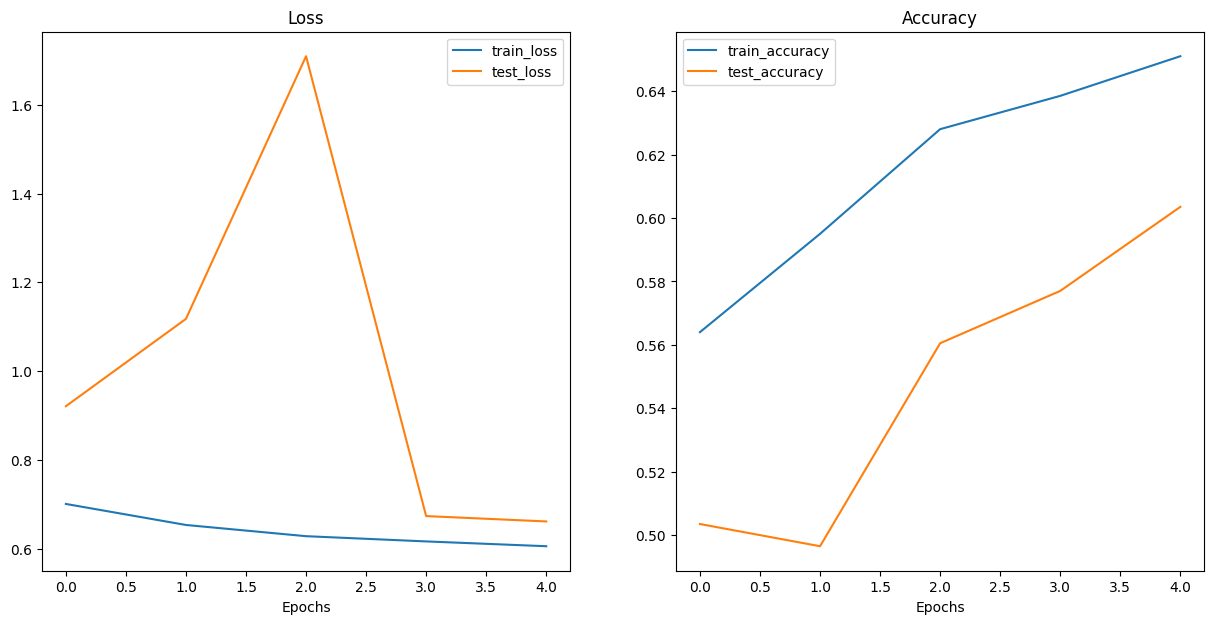
20%|████████████████▊ | 1/5 [00:51<03:24, 51.15s/it]
Epoch: 0 | Train loss: 0.7011 | Train acc: 0.5640 | Test loss: 0.9211 | Test acc: 0.5035
40%|█████████████████████████████████▌ | 2/5 [01:36<02:22, 47.66s/it]
Epoch: 1 | Train loss: 0.6538 | Train acc: 0.5950 | Test loss: 1.1178 | Test acc: 0.4965
60%|██████████████████████████████████████████████████▍ | 3/5 [02:12<01:25, 42.55s/it]
Epoch: 2 | Train loss: 0.6285 | Train acc: 0.6280 | Test loss: 1.7091 | Test acc: 0.5605
80%|███████████████████████████████████████████████████████████████████▏ | 4/5 [02:49<00:40, 40.15s/it]
Epoch: 3 | Train loss: 0.6168 | Train acc: 0.6385 | Test loss: 0.6738 | Test acc: 0.5770
100%|████████████████████████████████████████████████████████████████████████████████████| 5/5 [03:27<00:00, 41.41s/it]
Epoch: 4 | Train loss: 0.6060 | Train acc: 0.6510 | Test loss: 0.6617 | Test acc: 0.6035 Total training time: 207.058 seconds
Confusion Matrix:
[[249 10]
[188 33]]
Classification Report:
precision recall f1-score support
0 0.57 0.96 0.72 259
1 0.77 0.15 0.25 221
accuracy 0.59 480
macro avg 0.67 0.56 0.48 480
weighted avg 0.66 0.59 0.50 480
실제로 눈 감았는데, 감았다고 잘 예측한 거 249
실제로 눈 감았는데, 떴다고 잘못 예측한거 10
실제로 눈 떴는데, 감았다고 잘못 예측한거 188
실제로 눈 떴는데, 떴다고 잘 예측한거 33
클래스 0에 대한 precision : 0.57 - 눈 감고 있다고 예측한 샘플 중에서 실제로 눈 감고 있는 샘플의 비율.
클래스 0에 대한 recall : 0.96 - 실제로 눈 감고 있는 샘플 중에서 모델이 눈 감고 있다고 정확히 예측한 샘플의 비율 (높음!!)
위험한 오류→ 눈 감았는데, 떴다고 잘못 예측한거 (졸음운전 중인데, 정상이라고 예측한거니까)
여기서 다행히 이 값은 10으로 낮음.
ResNet이 VGG 보다는 훨씬 좋은 성능 보이고 있음
** 하지만 ResNet도 그렇게 높은 정확도를 보이고 있지 않으므로 디버깅을 통해 문제를 찾아내야 할듯 함
'Deep Learning & AI > CV' 카테고리의 다른 글
| [Paper Review] MetaFormer : A Unified Meta Framework for Fine-Grained Recognition (1) | 2024.07.08 |
|---|---|
| [Paper Review] CLIP (Learning Transferable Visual Models From Natural Language Supervision) (1) | 2024.07.01 |
| [VGG] 졸음운전 분류 프로젝트 (4) | 2024.03.11 |
| [CNN] 졸음운전 분류 프로젝트 (0) | 2024.03.04 |
| [CNN] 전이 학습 - 특성 추출 기법 (1) | 2024.01.01 |