

이번에 NUS MMRL에서 파견연구를 하게되면서 가장 먼저 읽어보라고 하신 CLIP 논문에 대해 리뷰해보겠다.
논문을 이해하는데에 참고한 블로그와 영상들이다.
https://greeksharifa.github.io/computer%20vision/2021/12/19/CLIP/
Python, Machine & Deep Learning
Python, Machine Learning & Deep Learning
greeksharifa.github.io
https://youtu.be/HkkaKI6NN-8?si=UvXCdFFS9hEYwwYy
논문 링크 : https://arxiv.org/abs/2103.00020
Learning Transferable Visual Models From Natural Language Supervision
State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their generality and usability since additional labeled data is needed to specify any other visual co
arxiv.org
Github : https://github.com/openai/CLIP
GitHub - openai/CLIP: CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image
CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image - openai/CLIP
github.com
CLIP 은 간단히 말해서, 이미지와 텍스트를 같은 공간에서 보내서 multimodal representain learning을 수행하는 모델이다.
Abstract
기존의 SOTA CV 시스템은 고정된 집합의, 미리 지정한 object category에 대해서만 예측을 수행하도록 학습했다. 이는 확장성, 일반성 등을 저해하며 데이터를 수집하기도 힘들다.
CLIP은 인터넷에서 얻은 대규모 데이터셋을 이용하여 이미지와 연관된 caption으로 사전학습한다. 그리고 자연어 지시문을 주면, zero-shot으로 모델을 downstream task에 적용할 수 있다.
결과적으로 OCR , action recognition 등 30개의 기존 task에서 좋은 성능을 보였다고 한다.
1. Introduction and Motivating Work
Bert나 GPT 등의 기존 연구들은 대규모 텍스트 데이터를 모아 사전학습(pre-training) 한 후에, 미세조정(fine-tuning)하는 방식으로 NLP 분야에서 매우 뛰어난 성과를 얻었다.
이미지 분야에서는 CNN 기반의 모델들이 강한 면모를 보이기는 하지만, zero-shot learning에서는 매우 낮은 정확도를 보인다.
본 논문에서는 4억 개의 이미지 + 텍스트 (caption) 쌍으로 대규모 학습한 모델로, 자연어 supervision을 사용하여 학습하였다. 그리고 매우 많은 vision task 에서 좋은 결과를 얻었다고 한다. 이제 어떤 방식으로 이렇게 좋은 결과를 얻을 수 있었는지 알아보자.
2. Approach
2.1 Natural Language Supervision
CLIP은 자연어를 supervision으로 주어 학습한다. 이는 새로운 아이디어는 아니지만, 기존의 많은 image dataset과는 달리 별도의 번거로운 labeling 작업이 필요없다는 강력한 장점을 가지고 있다. (이미 인터넷에서 라벨링된 대규모 데이터셋을 가져오니까)
또한, 이미지에 더해 자연어까지 representaion learning을 수행할 수 있고, 다른 종류의 task로도 유연하게 zero-shot transfer이 가능하다,

이런 걸 비전 분야에도 적용하자는 것! (raw text로부터 pre-train된 것)
-> Vision Language pre-train (Natural Language Supervision)
: 이미지랑 텍스트 pair data 이용해서 visual representation 학습!
2.2 Creating a Sufficientlly Large Dataset
장점)
- 크기를 키우기 쉬움 (인터넷에서 긁어온 데이터셋 활용하면 되니까 데이터셋 무한대 가능)
- 인터넷에 있는 많은 양의 텍스트 데이터로부터 수동으로 supervision 배울 수 있음
- vision representaion을 배움과 동시에 language representaion과 연결하는 방법도 같이 배움 -> zero-shot transfer flexible하게
** transfer learning이란?
: 특정 데이터로 이미 학습된 모델을 다른 태스크에서 재사용하는 기법

파란색처럼 pre-train을 먼저 진행한 이후에, downstream task를 진행하면서 knowledge를 transfer하는 개념
cf) ConVIRT나 VirTex도 이런거 제안했지만, 이들은 only 100,000 ~ 200,000 images…
=> CLIP은 40억개의 데이터셋 가지고 모델 학습시킴 from publicly available internet sources
=> train a simplified version of ConVIRT from scratch
=> CLIP (Contrastive Language-Image Pre-training)
- MS-COCO, Visual Genome : high quality / small (100,000)
- YFCC100M : varying quality / large(100M) -> after filtering -> 15M
-> CLIP 은 WIT(WebImageText)라는 새로운 데이터셋을 만들었다. (인터넷의 다양한 사이트에서 가져온 4억 개의 (image, text) 쌍)
cf) VirTex란,

2.3 Selecting an Efficient Pre-Training Method
: Contrastive Learning (ConVIRT에서 사용한 방식과 동일)
1개의 batch는 N개의 (image, text) 쌍으로 구성된다. 그러면 N개의 쌍을 모든 i,j에 대해서 비교하면 N개의 positive pair와 N**2 - N개의 negative pair를 얻을 수 있다.
- image mini batch, text mini batch 준비 (image와 text를 하나의 공통된 space로 보낸 다음)
-> N x N pair들 중에서 positive n개의 pair의 cosine similarity는 최대가 되게,
N**2-N개의 negative pair들의 cosine similarity는 최소가 되게 학습시킴 (이게 contrastive learning)
-> similarity score 계산해서 cross entropy loss 계산
=> 이 과정을 통해 CLIP은 multi-modal embedding space를 학습하게 됨


2.4 Choosing and Scaling a Model
위에 코드에서 image_encoder와 text_encoder 확인 가능
- Image encoder : 5 ResNets and 3 ViTs with some modifications
2개의 architecture 고려했다
1. ResNet-50에서 약간 수정된 버전인 ResNet-D 버전을 사용한다. Global Average Pooling을 Attention Pooling으로 대체하였다.
2. ViT도 사용한다. Layer Normalization 추가 외에는 별다른 수정이 없다
- Text encoder로는 Transformer(Sparse Transformer) 사용했다
max_length=76인데, 실제 구현체에서는 마지막 token을 고려해서인지 77로 설정되어 있다.
+ very large minibatch size(32,768)
+ many efforts to save memory and time (ex:mixed precisio)
+ the largest ResNet model (RN50x64) took 18 days to train on 592 V100 GPUs
+ ViT-L/14 performed best, so was used as a backbone for all experiments
2.5 Training
- ResNet은 ResNet-50, ResNet-101, ResNet-50의 4배, 16배, 64배에 해당하는 EfficientNet-style 모델 3개(RN50x4, RN50x16, RN50x64)를 추가로 더 학습시켰다.
- ViT는 ViT-B/32, ViT-B/16, ViT-L/14를 사용하였다.
- 전부 32 epoch만큼 학습시켰다.
3. Experiments
3.1 Zero-Shot Transfer
3.1.2 Using CLIP for zero-shot transfer
Pre-training 시킨걸로 downstream task에 transfer 해서 성능 보기
-> zero- shot prediction

(이미지 분류 task의 경우) 이미지가 주어지면 데이터셋의 모든 class와의 (image, text) 쌍에 대해 유사도를 측정하고 가장 그럴듯한(probable) 쌍을 출력한다.
구체적으로는 위 그림과 같이, 각 class name을 "A photo of a {class}." 형식의 문장으로 바꾼 뒤, 주어진 이미지와 유사도를 모든 class에 대해 측정하는 방식이다.
정리하자면,
- pre-training task : 어떤 caption이 어떤 이미지와 대응되는지 예측
- pre-training 이후 : natural language 이용하여 학습된 (또는 새로운) visual concept을 reference하는 데 이용
-> zero-shot transfer가 가능하게 함
3.1.3 Initial comparison to visual n-grams
이미지 분류 문제에서 visual n-grams 방식보다 실험한 3개의 데이터셋 모두에서 zero-shot 성능이 훨씬 뛰어나다.

- visual n-grams : 유일하게 pre-trained model 이용해서, 여러 task에 대해서 zero shot으로 transfer할 수 있는 유일한 모델
3.1.4 Prompt engineering and ensembling
- Prompt Engineering
: Encoder에 보낼때 ‘A photo of a (object)’ 이렇게 문장 형태로 고쳐서 보내는 것.
Prompt engineering 사용하지 않았을 때 common issue
1) Polysemy (다형성, 다의성) : 같은 단어의 multiple meaning이 각각 다른 class로 되는 경우
(ex. Crane : 크레인 / 학) -> 동음이의어 발생 가능 (인터넷에서 온갖 이미지 긁어온거라) -> class name 외에 추가적인 정보 없는 경우 다른 class 로 인식할 수 있는 문제 존재
2) Usually text is a full sentence in the training set
(pre-trainig dataset에서 이미지와 text pair된 text가 single word인 경우는 거의 없음)
(class name은 대부분 한단어 정도인데, 사전학습한 데이터는 그렇지가 않음, 그래서 class name 그대로 집어 넣어 유사도 측정하는게 아니라 문장형태 만들어서 유사도 측정하는 것,
Ex. 보통 인스타에도 그냥 dog 이라고 안하고 my pretty little dog 이런 식으로 문장 형태로 쓰니까 pre trained된 dataset도 문장형태로 되어있음)
-> ImageNet에서 정확도 1.3% 올라감
++ Customizing prompt text to each task
Ex1. A photo of a {label}, a type of pet
-> worked well on Oxford - IIIT Pets dataset

Ex2. a satellite phto of a {label}
-> Satellite Images에 성능 좋음
++ Ensemble of different context prompts
Ex. A photo of big {label} + A photo of a small {label}
- Ensemble over the embedding space(이미지랑 text dot product하기 전에 Encoder에서 각각 나온 상태에서 -> dot product는 원래대로 한번만) , instead of probaility space (마지막에 dot product해서 score 계산한 후에 score끼리 soft voting average 등.. 하는게 아니라!)
- ImageNet에서 80개의 서로 다른 context prompt 앙상블 했을 때 정확도가 3.5% 올라감.

3.1.5. Analysis of zero-shot CLIP performance
- (Compared w/ supervised model)

27개 중 16개의 dataset에서 CLIP이 더 좋은 성능을 보임.
dataset 특성별로 조금씩 성능 차가 다른데,
- Stanford Cars, Food101과 같은 fine-grained task에서는 성능이 크게 앞선다.
- OxfordPets, Birdsnap에서는 비슷비슷한데, 이는 WIT와 ImageNet 간에 per-task supervision 양의 차이 때문이라 여겨진다.
- STL10에서는 99.3%의 정확도로 SOTA를 달성했다.
- EuroSAT, RESISC45은 satellite image를 분류하는 데이터셋인데, 이렇게 상당히 특수하거나 복잡한 경우 CLIP의 성능은 baseline보다 많이 낮았다. 아마 사전학습할 때 그렇게 지엽적?인 정보는 학습하지 못했기 때문일 것이다.
=> video에서 action recognition하는 task에서는 visual representation을 배우면서 동시에 verb 를 포함한 natural language representation 같이 연결해서 배울 수 있어서 우월성 드러냄
<-> 위성사진 처럼 특이하고, 복잡하고, 추상적인 task에 대해서는 약함 (긁어온 data에 위성사진이나 medical image는 많이 없었을 것) -> 이러한 data 추가학습 필요
- (Compared w/ few-shot)
one-shot : training data 전혀 보여주지 않음
Few-shot : 각각 class에 속하는 sample들을 몇개만 보여주고 추론

one shot일 때 zero shot보다 성능이 떨어진 이유는,
Zero shot은 바로 임베딩 space에서 dot product해서 그걸로 score 계산하는데, few shot은 거기에 linear layer를 하나 덧붙여서 학습시킴
-> zero shot에서는 그 전에 자신이 알고 있던 지식으로 충분히 할 수 있는데 그걸 버리고 새로운 linear layer 하나를 scratch부터 학습시키는 거라서 오히려 성능이 저하됨.
-> training example 수가 충분히 주어지면 더 높은 성능 보임.
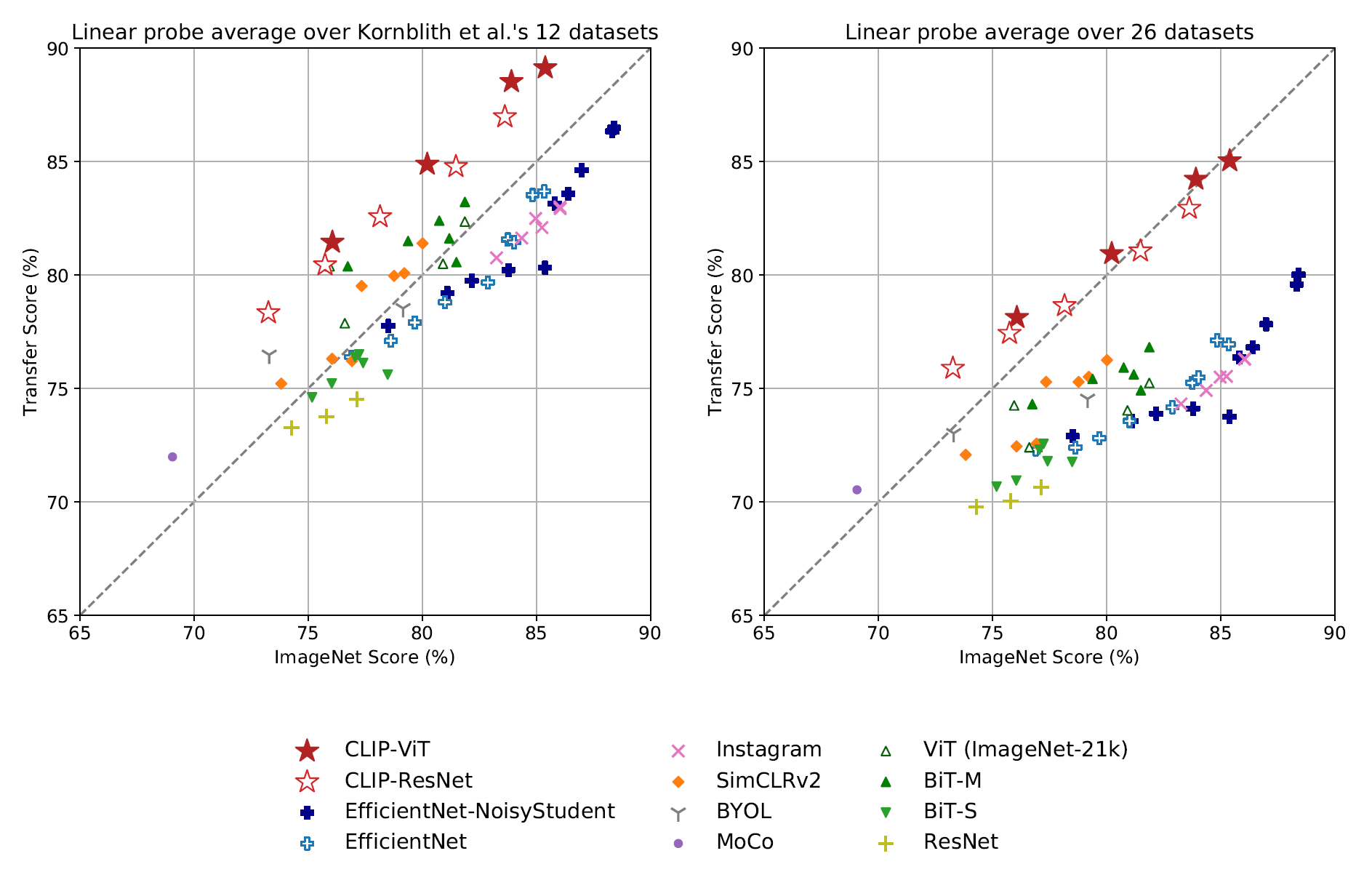
3.2 Representaion Learning
Image의 특성을 최대한 잘 설명하는 어떤 feature(representation)을 잘 뽑아 이를 다른 downstream task에 활용하겠다는 것인데, CLIP은 이런 image representation을 상당히 잘 뽑는 것 같다.
모델의 representation learning 성능은 뽑아진 representation을 선형모델에 넣은 성능으로 평가하며, CLIP 논문에서도 이와 같은 방법을 사용하였다.

작은 모델은 기존의 SOTA보다 조금 낮은 성능을 보이지만 가장 큰 모델인 ResNetx64, ViT 기반 모델의 경우 다른 모델에 전부 앞선다.
부록에서 qualitative example을 볼 수 있다.

EfficientNet과 비교해봐도 성능 좋다.

3.3 Robustness to Natural Distribution Shift
Distribution Shift
: 기계학습 모델의 경우 근본적으로 과적합 위험 및 일반화 실패의 가능성이 항상 있는데, 이는 training set과 test set의 distribution이 동일할 것이라는 가정에 기초해 있기 때문이기도 하다. 이러한 차이를 distribution shift라 한다.
CLIP은 이러한 Distribution Shift에 강건하다.
- task shift 에 관하여
다른 task로 transfer를 수행했을 때 CLIP의 representaion이 얼마나 더 나은지 보여줌

- ImageNet V1은 통상적인 바나나 상품 사진이라면,
- ImageNet V2는 좀 더 다양한 모양의 바나나 사진을,
- ImageNet-R은 실제 바나나 사진뿐만 아니라 그림이나 여러 변형이 일어난 사진
- ObjectNet은 다양한 배경이나 상황의 바나나 사진
- ImageNet Sketch는 바나나 스케치 사진
- ImageNet-A는 굉장히 다양한 구도의 바나나 사진
=> 각각 data distribution이 다를 것
-> ResNet101과 비교하여, CLIP은 zero-shot 성능을 위 데이터셋에서 비교했을 때 성능이 높음
= natural distributio shift에 강건하다.
= generalization 성능이 뛰어나다.
= bias가 덜 되어있다.
+ 논문에선 robustness를 두가지로 분류하고 있음
- Effective robustness: Distribution shift에서의 정확도 개선
- Relative robustness: Out-of-distribution에서의 정확도 개선
-> 모델의 robustness 높이려면 2가지 모두의 정확도 개선 필요
아래 그림은 ImageNet에 조금 더 adaptation을 시켰을 때(정확도 9.2% 상승),
모델의 전체적인 robustness는 조금 낮아졌음을 보여준다. 일종의 trade-off 존재

비슷하게, CLIP을 few-shot 학습을 시키면 해당 task는 더 잘 풀게 되지만, zero-shot CLIP에 비해서 robustness는 떨어진다.

'Deep Learning & AI > CV' 카테고리의 다른 글
| [Paper Review] Hyper-class Augmented and Regularized Deep Learning for Fine-grained Image Classification (0) | 2024.07.15 |
|---|---|
| [Paper Review] MetaFormer : A Unified Meta Framework for Fine-Grained Recognition (1) | 2024.07.08 |
| [ResNet] 졸음운전 분류 프로젝트 (1) | 2024.03.18 |
| [VGG] 졸음운전 분류 프로젝트 (4) | 2024.03.11 |
| [CNN] 졸음운전 분류 프로젝트 (0) | 2024.03.04 |